Optimizing Multi-Segment Distributed Storage in Kubernetes
Written on
Understanding Multi-Segment Distributed Storage
Collaborating with a team of researchers on the Calit2 project allowed us to explore an intriguing use case for EdgeFS, which involves stretching storage solutions within a single Kubernetes cluster and across continents via a high-throughput yet high-latency networking environment.
The challenge of transferring data over long distances at high speeds is not new, and organizations like Cenic have made strides in addressing it. However, sharing datasets among researchers—even within a dedicated DMZ—remains a complex endeavor, particularly regarding data management.
Latency issues are prevalent across different geographical locations, even with advanced optical backbones, making the stretching of a single storage namespace inefficient. Datasets can be widely dispersed, with some being quite large. When data is duplicated, it complicates security and consistency, but fortunately, not all datasets need to be accessed simultaneously.
This is where EdgeFS comes into play.
What is EdgeFS?
EdgeFS is a new addition to the CNCF Rook project, serving as a scalable storage solution. While it can function as a distributed storage cluster, it also offers a "solo" mode—operating as a single-node Docker container that can easily scale by integrating additional nodes or geographically dispersed segments.
One of the standout features of Kubernetes is its built-in namespace isolation, which allows for straightforward segmentation within the same cluster. Below is a visualization illustrating how EdgeFS segments can be distributed globally within a Kubernetes environment:
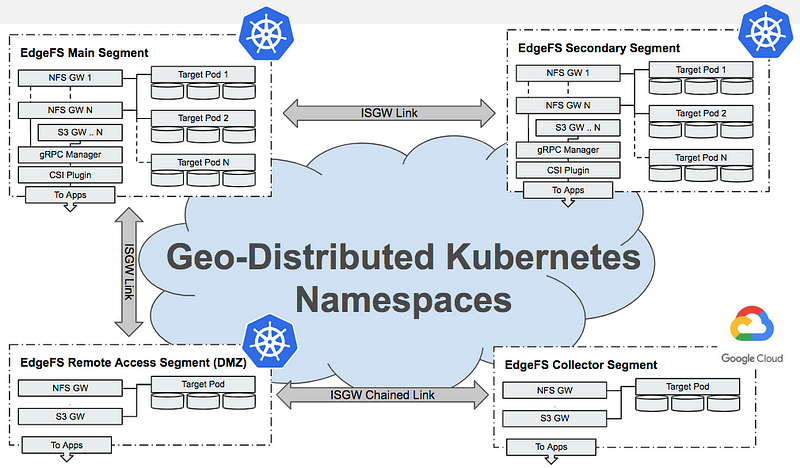
Each EdgeFS segment can exist within a single Kubernetes cluster as a designated namespace or across multiple clusters. Intersegment Gateway links (ISGW) can facilitate various use cases, such as:
- Establishing bi-directional connections between segments in master-master or master-secondary configurations.
- Connecting segments in a star-like topology, where one central segment redistributes subscribed datasets.
- Enabling circular-like topologies that propagate modifications across neighboring segments.
- Allowing remote access to fully replicated datasets or metadata-only replicated datasets, fetching data chunks on demand.
When set up within a single Kubernetes cluster, each EdgeFS segment will utilize its own namespace, which is the focus of this article. Let’s dive into the setup process!
Configuring EdgeFS with Rook
Using the Rook EdgeFS operator, we can configure two or more segments within the same Kubernetes installation. This is particularly useful when Kubernetes nodes are dispersed across different regions, where cross-region latency may be significant, or links might experience temporary outages.
EdgeFS ISGW links can be established to ensure synchronization of all segments on a per-bucket basis. Each segment requires a unique regional sub-namespace, localized for tenants and their users. For instance, syncing segments within the same global namespace would appear in efscli as follows:
# efscli cluster list
SanFrancisco
NewYork
# efscli tenant list SanFrancisco
Biology
MedicalSupply
# efscli tenant list NewYork
Marketing
Finance
Configuring Segments
Ensure that each segment is configured within its respective Kubernetes namespace. To do this, copy the cluster.yaml Custom Resource Definition (CRD) file and modify all instances of:
- Namespace name
- PodSecurityPolicy metadata name
- ClusterRole metadata name
- ClusterRoleBinding system-psp and cluster-psp metadata name and roleRef
Create a new cluster CRD and verify that it is generated within its designated namespace. Be cautious about the filtering node and device selectors, as node devices cannot be shared across namespaces.
The final configuration might resemble the following:
# kubectl get svc -n rook-edgefs-sanfrancisco
NAME
rook-edgefs-mgr
rook-edgefs-restapi
rook-edgefs-target
rook-edgefs-ui
# kubectl get svc -n rook-edgefs-newyork
NAME
rook-edgefs-mgr
rook-edgefs-restapi
rook-edgefs-target
rook-edgefs-ui
This indicates that each cluster segment has its own management endpoints while being overseen by the same Rook Operator instance.
Configuring Services
Once all EdgeFS targets for a new segment are operational, confirm that the EdgeFS UI is accessible and capable of creating Services CRDs. When generating services, it will automatically select the Kubernetes operating namespace for the CRD's metadata.
For those who prefer command-line operations, you can manage cluster segments via the neadm management command, such as:
neadm service enable|disable NAME
This will create or delete CRDs similarly to the GUI, utilizing the same REST API calls. Alternatively, you can manually prepare the CRD YAML file according to Rook's documentation and specify the target Kubernetes namespace.
Configuring the CSI Provisioner
As of the time of writing, CSI Topology Awareness is still in Beta, and thus, the EdgeFS CSI driver does not yet support it. However, advancements have been made to facilitate Multi-Segmented usage in the latest EdgeFS CSI provisioner.
To configure, edit the configuration secret file and add:
k8sEdgefsNamespaces: [“rook-edgefs-sanfrancisco”, “rook-edgefs-newyork”]
For dynamically provisioned volumes, include the segment's name and EdgeFS service name in the storage class YAML file:
parameters:
segment: rook-edgefs-sanfrancisco
service: nfs01
When scheduling a new pod, ensure that the volume specifies the segment's namespace and EdgeFS service name:
volumeHandle: sanfrancisco:nfs01@cluster/tenant/bucket
With these configurations, a single instance of the EdgeFS CSI provisioner can manage topology-aware PV/PVC orchestration, allowing requests for NFS or iSCSI PVs to be directed to the specified region.
Summary
While I generally recommend utilizing federated Kubernetes clusters, it is important to recognize the benefits of single-cluster flat networking, such as simplified management, lightweight namespace isolation, and the absence of complex federation replication.
With EdgeFS integrated into the setup, cross-region data access can be effortlessly configured and tightly integrated with Kubernetes through the Rook Operator and CSI Provisioner. Once established, Kubernetes PVs can easily float between data segments without introducing additional data management complexities. Simply reschedule a pod in a different segment, redirect to the synchronized bucket, and access the dataset instantly.
Even when data updates are not fully synchronized, EdgeFS guarantees the consistency of locally synced reads. By leveraging the Metadata-Only syncing feature, consistent datasets can be distributed rapidly, with data chunks available on demand.
Try it out today!
Follow us in the EdgeFS and Rook communities!
Exploring EdgeFS Solutions
The first video titled "Persistent Storage with Kubernetes in Production - Which Solution and Why?" provides insights into selecting the right persistent storage solutions for Kubernetes deployments.
Getting Started with Longhorn
The second video, "[Kube 102] Getting started with Longhorn | Cloud Native Distributed Storage for Kubernetes," offers an introduction to using Longhorn for cloud-native distributed storage in Kubernetes environments.