Mastering Q&A with BERT: Unleashing Transformer Potential
Written on
Chapter 1: The Evolution of Q&A Systems
In the past, the idea of querying machines for answers felt like something out of science fiction. However, today, we interact with question-and-answer systems so frequently that we often overlook their significance. A prime example of this is Google Search. While many use it primarily for information retrieval, a substantial number of queries are direct questions that Google adeptly answers.

Asking Direct Questions
Google has mastered the art of recognizing various types of queries, including mathematical problems. It can even provide tailored responses based on specific locations and times. While Google leads the field, we can still create impressive Q&A systems using the same models that power Google’s technology.
In this guide, we’ll delve into how to implement cutting-edge transformer models for Q&A tasks, focusing on Google’s BERT model. Our exploration will encompass:
HuggingFace's Transformers
Installation Steps
Setting Up a Q&A Transformer
Locating a Model
The Q&A Pipeline
- Model and Tokenizer Initialization
- Tokenization Process
- Pipeline and Prediction
For those who prefer visual learning, you can find a comprehensive video guide here:
Chapter 2: Understanding HuggingFace’s Transformers
Transformers have revolutionized natural language processing (NLP), emerging as remarkable models since their introduction in 2017. The HuggingFace library is pivotal for implementing these transformers in practical applications.
The library's popularity stems from several key factors:
- Open-source: The library is freely available and supported by a vibrant community.
- Ease of Use: Users can deploy advanced models from Google, OpenAI, and Facebook with minimal code.
- Diverse Models: HuggingFace hosts an extensive collection of models that can be easily downloaded and utilized.
Installation Steps
To begin using transformers in Python, run the following command:
pip install transformers
This library requires either PyTorch or TensorFlow, which can be installed with:
pip install tensorflow
or
conda install tensorflow
Setting Up a Q&A Transformer
After installing the transformers library, we can start building our Q&A transformer script.
Finding a Model
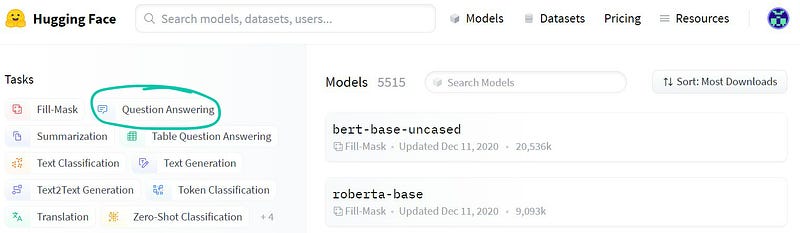
To select a model, visit huggingface.co/models and filter by Question-Answering.
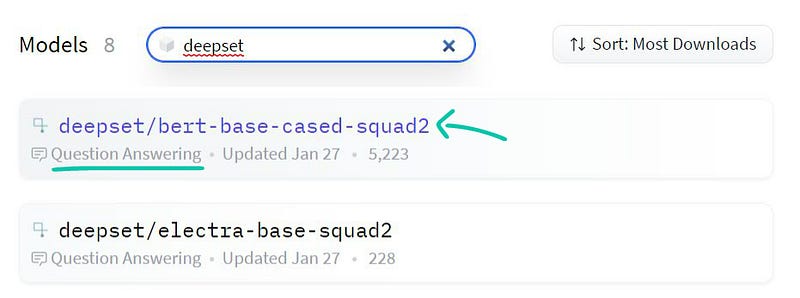
We’ll utilize two models from Deepset.AI: deepset/bert-base-cased-squad2 and deepset/electra-base-squad2. Both are pre-trained on the SQuAD 2.0 dataset, making them ideal for our purposes.
The Q&A Process
The fundamental process for question answering involves three key stages:
- Model and Tokenizer Initialization: Here, we import the transformers library and initialize our model and tokenizer using deepset/bert-base-cased-squad2.
- Input Data Tokenization: Next, the tokenizer converts human-readable text into token IDs that BERT can understand.
- Pipeline and Prediction: Finally, we integrate our initialized model and tokenizer to facilitate the question-answering process. The code is remarkably straightforward:
from transformers import pipeline
nlp = pipeline('question-answering', model=model, tokenizer=tokenizer)
With this setup, we can begin posing questions directly.
The Pipeline Process
When we feed a question and the context into our model, the input must adhere to a specific format:
[CLS] <context> [SEP] <question> [SEP] [PAD] [PAD] ... [PAD]
BERT processes this input, performs linguistic analysis, and identifies the answer span within the context. The identified indices indicate the start and end of the answer.
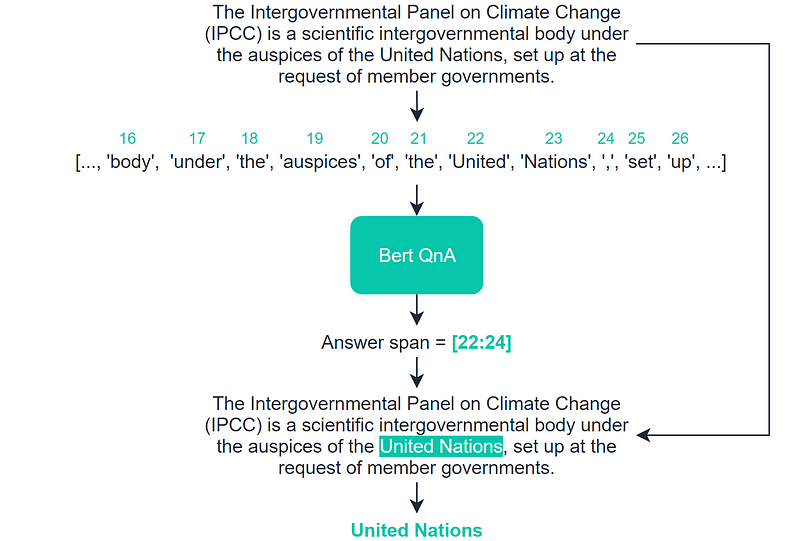
The pipeline extracts relevant token IDs based on BERT’s predictions, converting them back into human-readable text to provide the final answer.
Additional Considerations
While we've outlined the core components of building a Q&A transformer, there are other considerations for real-world applications, including context extraction and model fine-tuning. These aspects can enhance the effectiveness of your Q&A systems.
If you're interested in diving deeper into these topics, I’ve covered them extensively in my articles and video tutorials.
Thank you for reading! Feel free to share your thoughts or inquiries in the comments or reach out via Twitter.