Implementing MapReduce in Golang for Efficient Word Counting
Written on
Understanding the MapReduce Model
In today's Big Data landscape, efficient methods for data processing are critical. One of the most widely used frameworks for managing large datasets is the MapReduce model. This model breaks down tasks into smaller segments that can be executed simultaneously across various systems. In this discussion, we will explore how to utilize the MapReduce model with Go, a robust language well-suited for concurrent programming.
What Is the MapReduce Model?
The MapReduce framework is designed to efficiently handle extensive data volumes in a distributed environment. It comprises two main phases: the Map phase, which converts input data into intermediate key-value pairs, and the Reduce phase, which consolidates these intermediate pairs into a smaller set of values.
Golang's Role in Big Data Processing
Due to its high efficiency and built-in support for concurrency, Golang is an ideal choice for implementing a simplified version of the MapReduce model—an effective technique for processing and analyzing large datasets. In this article, we will develop a MapReduce algorithm specifically for counting words across several documents.
Our objective is straightforward: given multiple documents, we will count how frequently each word appears across all of them. The MapReduce framework is particularly suited for this task, as it allows for the parallel processing of individual documents during the Map phase and subsequent aggregation of the results in the Reduce phase.
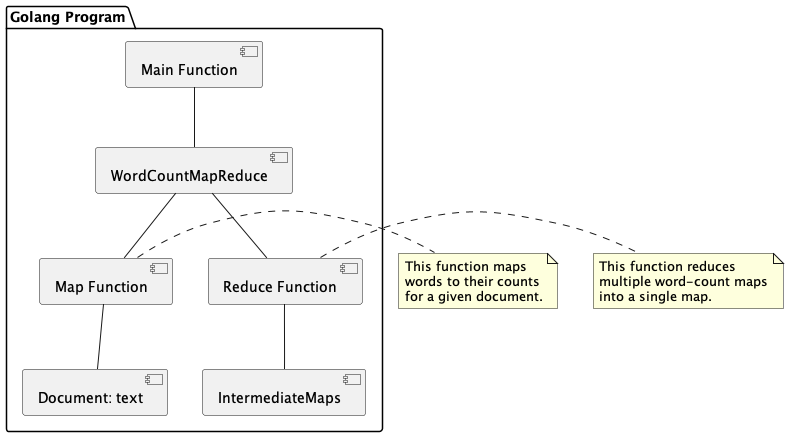
Defining Data Structures
We start by creating a structure for our Document. Each Document will have a name and a text field.
// Document represents a document to be processed.
type Document struct {
name string
text string
}
Here, the name field indicates the document's identifier, while the text field contains the actual content.
The Map Phase
During the Map phase, we will process each document individually. For each document, our goal is to tally the occurrences of each word. We will define a mapFunc function that takes a document's text as input and returns a mapping of words to their counts.
// mapFunc will take a document text and map each word to its count
func mapFunc(text string) map[string]int {
// Initialize an empty map to store the word counts
wordCounts := make(map[string]int)
// Split the text into words
words := strings.Fields(text)
// Count each word's occurrences
for _, word := range words {
wordCounts[word]++}
return wordCounts
}
The mapFunc function initializes an empty map called wordCounts to store the counts. It then splits the document's text into words using strings.Fields(text), incrementing the count for each word in the map.
The Reduce Phase
The Reduce phase combines the results from the Map phase into a final output. We will develop a reduceFunc function that accepts a slice of word-count maps and returns a consolidated word-count map.
// reduceFunc will take a slice of maps and reduce them into a single map
func reduceFunc(intermediateMaps []map[string]int) map[string]int {
// Initialize an empty map to store the final word counts
finalWordCounts := make(map[string]int)
// Combine counts from each intermediate map
for _, interMap := range intermediateMaps {
for word, count := range interMap {
finalWordCounts[word] += count}
}
return finalWordCounts
}
The reduceFunc initializes a new map, finalWordCounts, to keep the total counts. It iterates through each intermediate map, updating the total counts for each word in the final map.
Bringing It All Together
Now, we will integrate everything in the wordCountMapReduce function. This function accepts a slice of Documents, executes the Map and Reduce phases, and returns the final word-count map.
// wordCountMapReduce will take a slice of documents and return a map of word counts using the map-reduce pattern.
func wordCountMapReduce(documents []Document) map[string]int {
// Create a slice for intermediate results
intermediateMaps := make([]map[string]int, len(documents))
var wg sync.WaitGroup
wg.Add(len(documents))
// Map phase
for i, doc := range documents {
go func(i int, doc Document) {
defer wg.Done()
intermediateMaps[i] = mapFunc(doc.text)
}(i, doc)
}
// Wait for all map operations to complete
wg.Wait()
// Reduce phase
finalResult := reduceFunc(intermediateMaps)
return finalResult
}
In this code, we utilize Golang's goroutines along with a WaitGroup to ensure that all mapping operations are finished before proceeding to the reduction phase.
The main function initiates the entire process:
func main() {
// Sample documents
documents := []Document{
{
name: "Document1",
text: "the cat in the hat",
},
{
name: "Document2",
text: "the cat and the dog",
},
{
name: "Document3",
text: "the dog and the log",
},
{
name: "Document4",
text: "the log on the bog",
},
}
finalResult := wordCountMapReduce(documents)
fmt.Println(finalResult)
}
Conclusion
The MapReduce model offers a robust and scalable approach for handling extensive data. By breaking down tasks into manageable parts, it enhances performance through distributed processing across multiple machines.
In this article, we demonstrated a simplified version of MapReduce in Golang, an ideal language for such operations due to its inherent support for concurrency. By leveraging Golang's efficient concurrency primitives, we processed multiple documents in parallel during the Map phase and aggregated the results in the Reduce phase.
We employed Golang's goroutines and sync.WaitGroup to ensure all mapping tasks were completed before moving on to the reduction phase. Our example focused on counting words across various documents, providing a classic illustration of the MapReduce model.
The true potential of the MapReduce framework shines when applied to massive datasets, distributed systems, and complex computations. Nevertheless, this simplified example serves as a foundation for understanding how to implement the MapReduce model in Golang.
With a solid grasp of the principles behind MapReduce, you are now equipped to apply this model to more intricate scenarios and larger datasets.
Level Up Coding
Thank you for being a part of our community! Before you leave, consider:
- Clapping for this article
- Following the author
- Exploring more content in the Level Up Coding publication
- Joining our free coding interview course
- Following us on Twitter | LinkedIn | Newsletter
The first video titled "Golang Word Count" provides an in-depth look at implementing word counting in Go using the MapReduce model.
The second video, "Understanding Word Count Program with Map Reduce (With Demonstration)," offers a practical demonstration of the word counting program using MapReduce.