Effective Strategies for Managing Technical Incidents at Scale
Written on
Understanding Technical Incident Management
In the realm of software engineering, technical mishaps are an inevitability. As systems grow in complexity, the likelihood of encountering failures increases. For businesses experiencing rapid growth, a malfunctioning system can lead to significant revenue loss and a negative user experience. Therefore, maintaining a vigilant stance to swiftly address issues as they arise is crucial; customer retention hinges on smooth functionality.
Even with the most skilled engineers and adherence to best practices, systems are bound to fail eventually. Acknowledging this reality is essential for developers.
So, how does one effectively prepare for inevitable system failures? The solution lies in robust incident management.
How to Implement Effective Incident Management
Companies that operate large-scale services around the clock must prioritize incident management. Complacency is not an option in this field.
In my experience, I've identified a common framework for incident management in complex systems:
- Metric Emission: Each service transmits metrics to a centralized system for storage, typically utilizing a time-series database that captures key-value pairs.
- Visualization: A separate system queries this stored data and presents it visually in a user-friendly format, updating regularly.
- Dashboard Creation: A dashboard consolidates various metrics associated with the service for better visibility.
- Alerting Rules: As the system consistently queries metrics, rules are established to trigger alerts in an alert management system.
- Alerts and Notifications: Upon receiving an alert, the system notifies the responsible engineers through communication channels.
An Incident Management Framework
To illustrate these concepts more clearly, consider the following diagram:
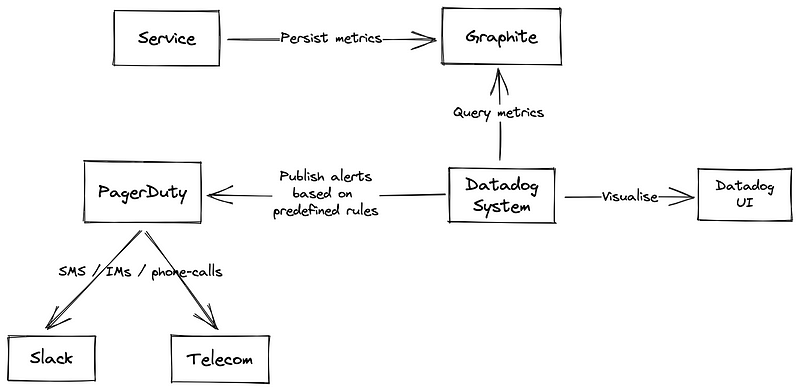
When designing an automated incident management architecture for a critical service, the diagram above presents a viable solution.
- Service Monitoring: Identify the key service you wish to monitor closely for any failures.
- Graphite: A well-known tool for storing metrics in time-series format, crucial for tracking service performance over time.
- Datadog: A comprehensive monitoring solution that retrieves metrics from Graphite for visualization and alerting.
- PagerDuty: A leading alert management system that notifies engineers via various communication tools, such as Slack and SMS, about any issues.
Understanding Responsibility and Response
One pressing question arises: who handles the alerts?
Companies typically establish on-call policies, ensuring at least one engineer is available at all times to respond to alerts. Here's a simplified breakdown:
- The service ownership team configures on-call schedules in PagerDuty, often rotating responsibilities among team members.
- On-call engineers serve as the initial responders to alerts, expected to react promptly.
- Upon notification, they acknowledge the alert, signaling their readiness to address the issue.
- Escalation policies are also set; if an engineer fails to respond within a specified timeframe, the alert escalates to a higher authority, such as the team manager.
Importantly, resolving an issue doesn't rest solely on the on-call engineer. They can seek assistance from other engineers by triggering alerts for additional support as needed.
While the main goal is to swiftly mitigate the issue, identifying the root cause can occur later. For instance, if a service experiences out-of-memory errors following a deployment, the on-call engineer should focus on reverting the changes rather than pinpointing the exact code responsible right away.
Post-Incident Actions
Once an incident has been resolved, the process does not end there. It's essential to implement steps aimed at preventing future occurrences. Companies with strong engineering cultures typically adopt the following practices:
- A postmortem or Reason for Outage (RFO) document is created, detailing the incident without attributing blame.
- Stakeholders review the document, often in regular RFO meetings.
Key questions addressed in the RFO include:
- What caused the incident?
- What actions were taken to mitigate it?
- How could the response have been improved?
- What was the timeline of events?
- What was the business impact?
- What measures will be implemented to prevent recurrence?
The focus here is on providing comprehensive information to share knowledge across teams, thereby minimizing the likelihood of similar issues in the future.
Designing a resilient system is challenging, and safeguarding it from failures is even more so. This is where effective incident management practices become invaluable. — Your humble author
Thank you for engaging with this discussion on incident management in technology firms. I hope you found it insightful!
Until next time, take care!
Additionally, I have launched my own newsletter! Every two weeks, I share curated articles on software engineering, covering topics like distributed systems, microservices, and industry best practices. If you're interested in enhancing your knowledge, feel free to subscribe!
Help, I Broke the Internet: Incident Management at Scale - This video discusses the complexities of managing incidents in large systems and offers insights on effective strategies.
Resolve Incidents Faster: Transforming Your Incident Management Process - This video focuses on innovative methods to streamline incident management processes for quicker resolutions.